

Richardson Maturity Model
A roadmap for your API development from the basics of request-response to the holy grail of HATEOAS.

Ever wondered why some APIs feel like a dream to work with, while others feel like navigating a labyrinth?
What if I told you that the difference between an API that's merely good and one that's truly great could be measured?
Richardson Maturity Model is a measure used to gauge the maturity of a RESTful API.
This model, proposed by Leonard Richardson, is divided into four levels, from Level 0 to Level 3, with each level introducing more sophisticated RESTful principles, culminating in the concept of HATEOAS (Hypermedia as the Engine of Application State).

Let's go through RMM using the example of an online bookstore system.
I will illustrate how the system's web service evolves from Level 0 to Level 3, showcasing the benefits and changes at each stage.
Level 0: The Swamp of POX

At Level 0, the online bookstore API does not adhere to REST principles.
It has a single entry point for all interactions, such as fetching book information, placing an order, or updating user profiles. Clients communicate with the service using only POST requests.
There's no standard mechanism to manage state or leverage HTTP's built-in capabilities.
This level is characterized by its simplicity but also its limited use of HTTP's potential and is reminiscent of SOAP-based services.
Such APIs are still found in legacy systems where changing architectural styles would require significant refactoring.
However, for new developments, you should avoid it in favor of more RESTful approaches.
Level 1: Resources
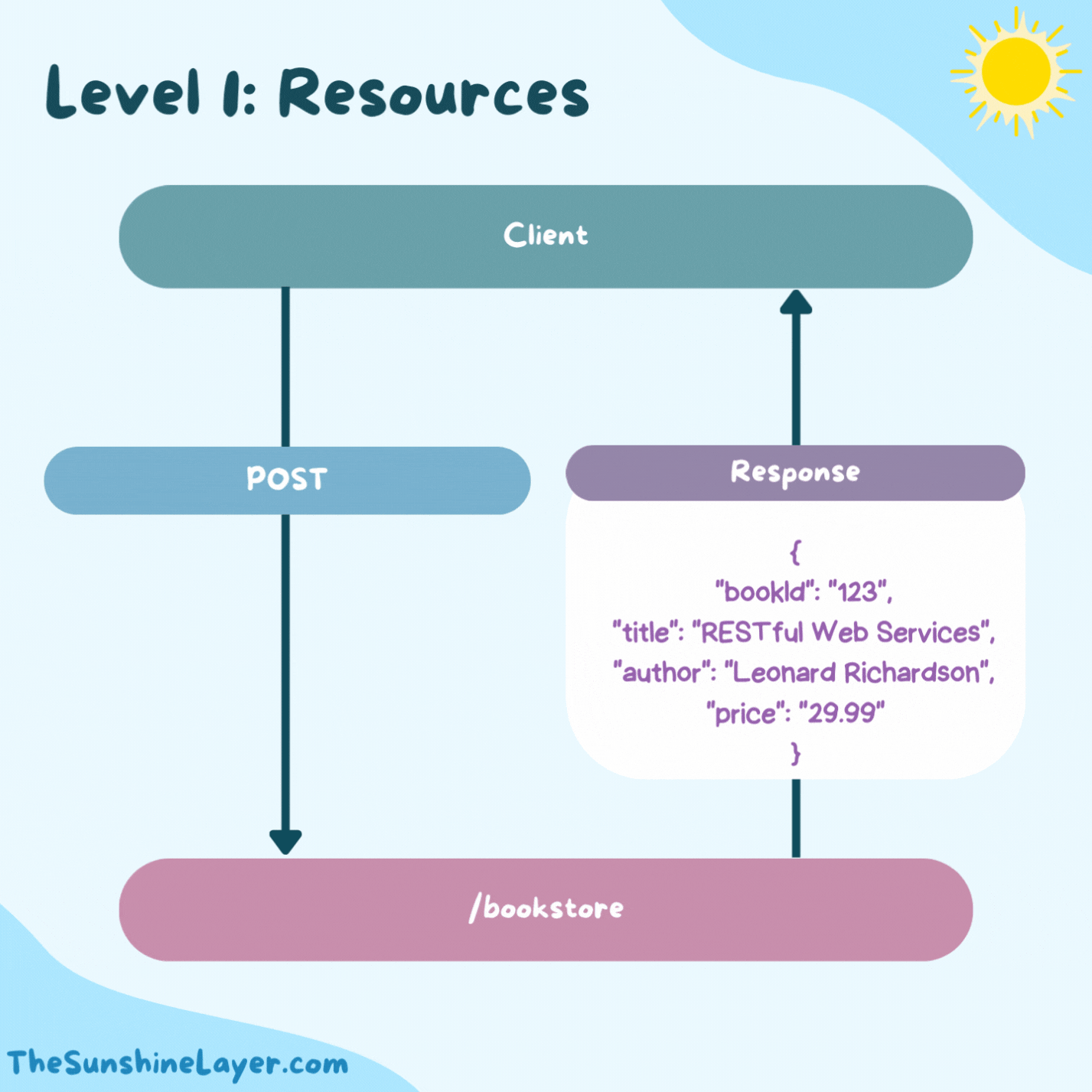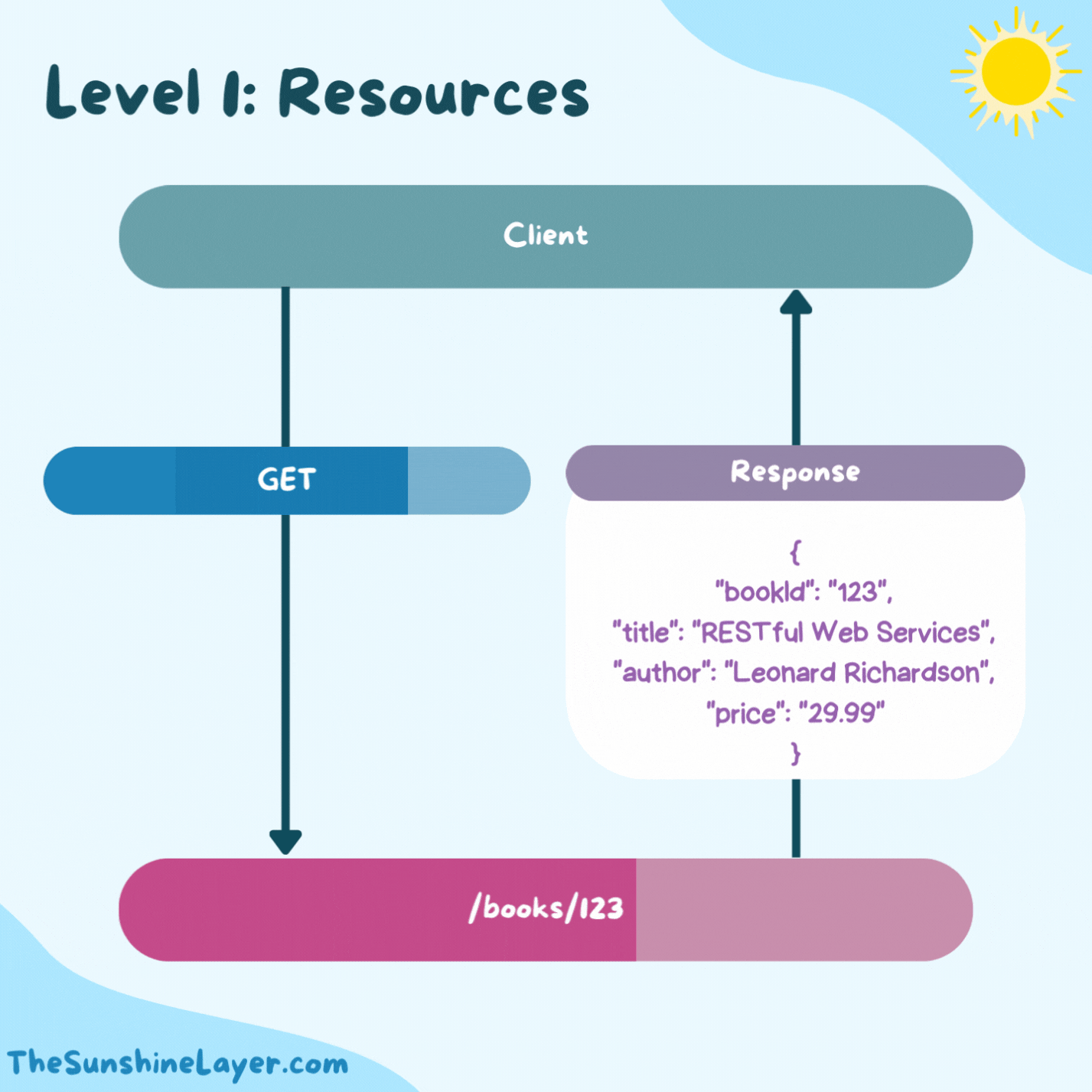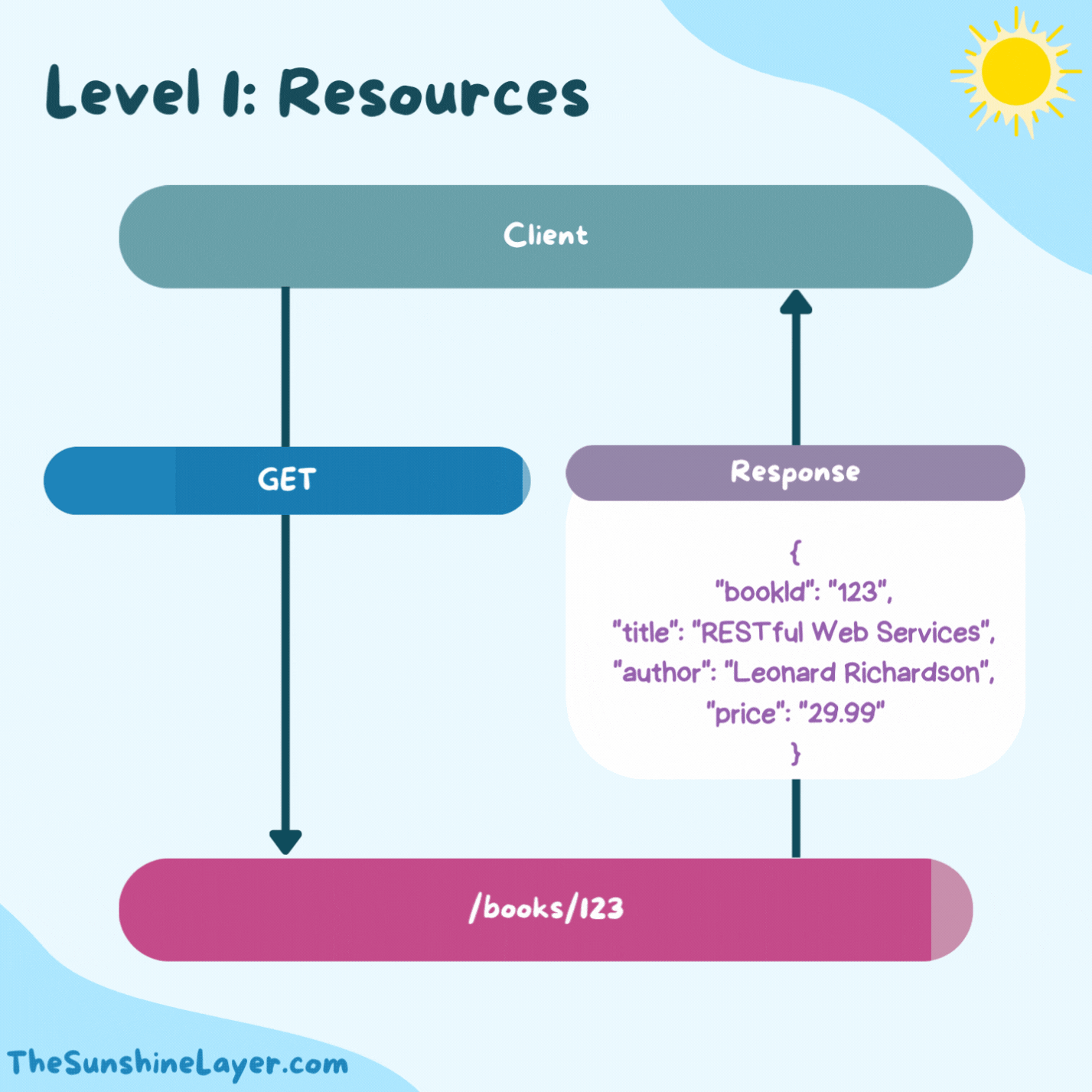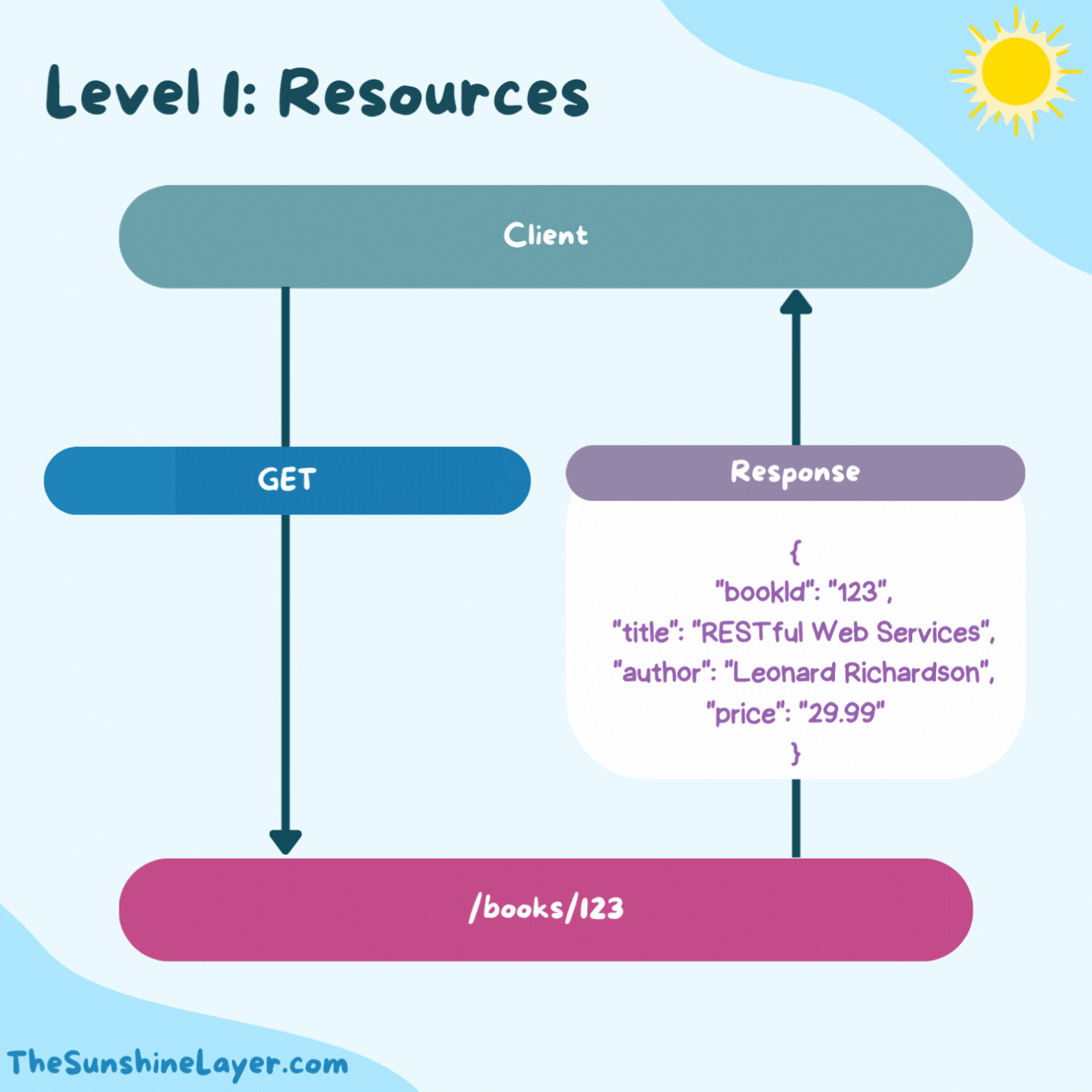
This level introduces the concept of individual resources.
The bookstore service starts to differentiate between types of resources by assigning them unique URIs. For instance, individual books, users, and orders each get their own URI.
To get information about a book, a client now sends a GET request to a specific book URI.
The response structure remains similar but is accessed through a more specific, resource-oriented URL.
This marks a significant step towards RESTful design by recognizing that different data entities should have separate URIs.
Level 1 is widely adopted as the minimum standard for web APIs.
It simplifies the design by allowing direct access to specific resources but does not leverage the full power of HTTP.
The resources should be plural nouns. Using verbs in URI is bad practice.
Level 2: HTTP Verbs

At Level 2, the bookstore service begins to utilize HTTP verbs appropriately to define actions on resources.
This aligns the actions with the type of request being made, such as GET for retrieval, POST for creation, PUT for updates, and DELETE for deletions.
To place a new order, a client now uses POST to an orders resource, with a payload specifying the order details, such as the book ID and quantity.
To update a book, a client uses PUT, specifying the book ID and providing the new data.
This not only adheres to the principles of REST, but also enhances semantic clarity and the potential for caching.
Level 2 is considered a best practice for RESTful API design. It's commonly seen in web services, offering a balance between simplicity and the expressive power of HTTP.
Level 3: Hypermedia Controls (HATEOAS)
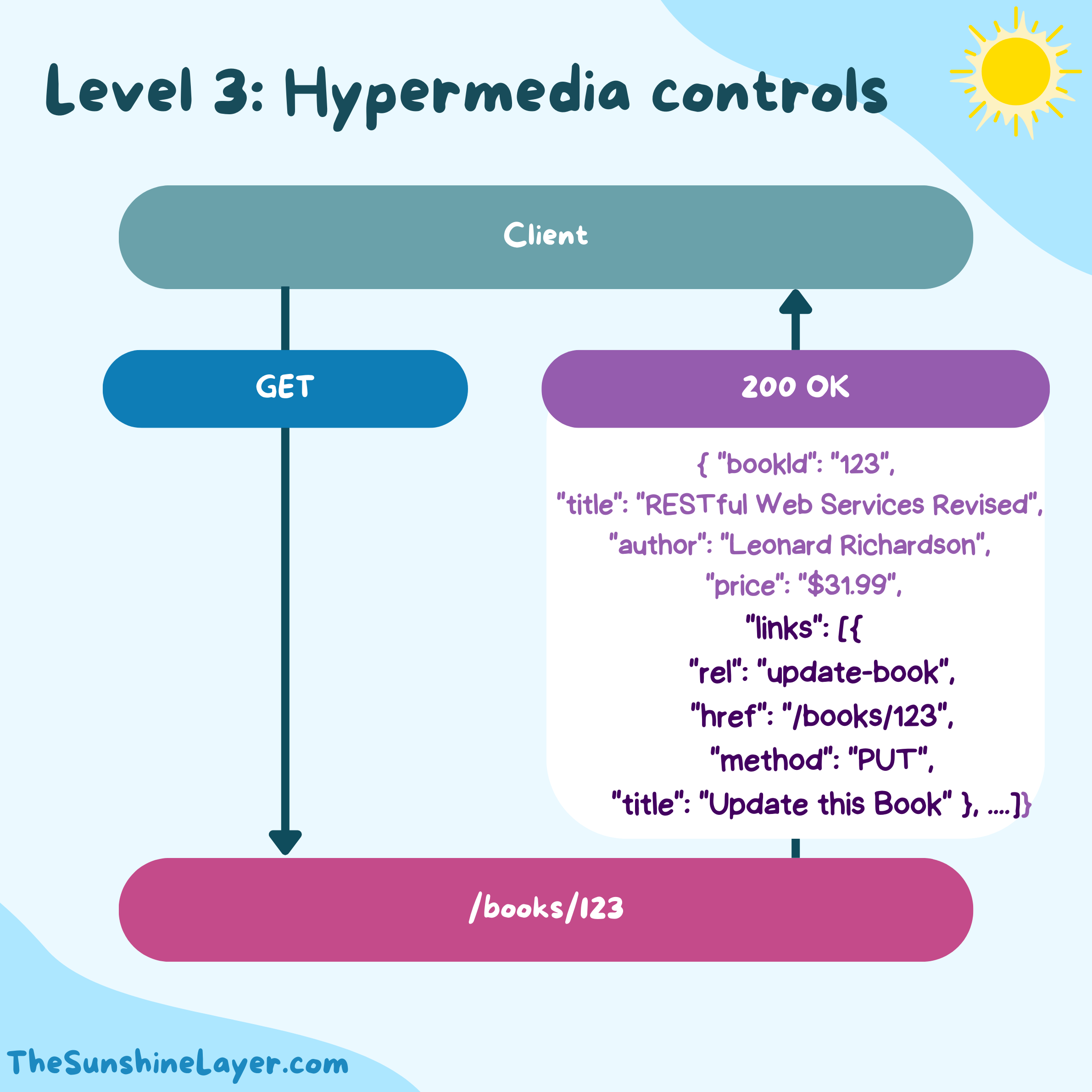
The highest maturity level introduces Hypermedia as the Engine of Application State (HATEOAS). At this stage, responses include hypermedia controls, guiding clients on potential actions through links within the response, making the API self-descriptive and fully navigable.
A response not only includes details about the book but also links for actions such as placing an order.
Despite its benefits, Level 3 has been slower to gain widespread adoption.
Challenges include increased complexity in client implementation and a lack of tooling support.
However, it's seen as the gold standard for RESTful design, promoting loose coupling and evolvability.
Strong APIs that require a high degree of discoverability and flexibility implement HATEOAS principles.
10 Questions & Considerations:
1. REST, RESTful or REST HATEOAS?
REST is the architectural style underlying the web, focusing on stateless communication, resource identification, and the use of standard HTTP methods.
RESTful APIs are those that adhere to REST principles, aiming for a stateless, cacheable, and layered system with uniform interfaces.
HATEOAS (Hypermedia as the Engine of Application State) is a component of RESTful APIs, requiring responses to include hyperlinks to other actions and resources, allowing for dynamic client navigation and coincides with Level 3 of RMM.
2. What Are the Purposes of Different HTTP Verbs?
Understanding the purpose of HTTP verbs and their proper use is crucial in designing RESTful APIs and ensuring they are both intuitive and adhere to web standards. Here's a detailed look at the key HTTP methods, their intended actions, and guidance on some common edge cases.

GET
Purpose: Retrieve data from a server at the specified resource. GET requests should be idempotent, meaning multiple identical requests should have the same effect as a single one.
Actions: Used to request data without causing any side effects. This is the method used for searching or querying resources with specific parameters.
HEAD
Purpose: The HEAD method is used to retrieve the headers of a resource, without the body. It's essentially a GET request without the response body. This is useful for checking what a GET request will return in terms of headers, status code, or to verify if a resource exists before downloading it.
Actions: Used to check if a resource exists. It can verify if there have been modifications to a resource (using headers like Last-Modified or ETag). Can also check the size of a resource before downloading it, via the Content-Length header.
POST
Purpose: Submit data to the server to create or update a resource, or trigger a non-idempotent operation. It does not require the client to know the resource's URI beforehand.
Actions: Used for creating new resources, submitting form data, or triggering operations that change the server's state.
PUT
Purpose: Replace the target resource with the request payload.
It is idempotent, meaning subsequent identical requests should ensure the same state on the server.
Actions: Typically used for updating existing resources in their entirety or creating a resource at a specific URL if it doesn't exist.
PATCH
Purpose: Apply a partial update to a resource. Like PUT, it is intended for modifying resources but only changes the parts specified in the request.
Actions: Ideal for updating only a subset of a resource's data, making it more efficient than PUT for large resources with minor changes.
DELETE
Purpose: Remove the specified resource from the server.
Actions: Used to permanently delete a resource. It is idempotent, as the resource remains deleted after multiple identical requests.
OPTIONS
Purpose: Describes the communication options for the target resource. It's used to discover which HTTP methods are supported by a web server for a given resource. This can be particularly useful in RESTful APIs for supporting cross-origin resource sharing (CORS) preflight requests.
Actions: Used to determine the HTTP methods (GET, POST, PUT, PATCH, DELETE, etc.) that a server supports for a specific URL. Can check for CORS policies by revealing allowed origins, HTTP methods, and headers. It’s also useful in assisting in the exploration and debugging of APIs by providing information about how to interact with a resource.
3. Are HTTP Methods Idempotent?
GET, HEAD, PUT, DELETE and OPTIONS are considered idempotent, meaning repeating the requests multiple times has the same effect as making a single request.
POST is not idempotent, as repeating a POST request can create multiple resources or trigger the operation multiple times. Patch can be idempotent, but it’s not a guarantee.
4. Can GET Requests Have Bodies? Should They?
While technically possible, GET requests with bodies are not recommended and widely unsupported, as most servers ignore it.
It's not standard practice to send a body with GET requests, and doing so can lead to unpredictable behavior.
GET requests should convey requests via URI and query parameters, adhering to the HTTP specification and ensuring compatibility and predictability across web services.
This allows filtering or paging resources without changing the server's state, hence maintaining idempotency.
For complex queries that do not fit well within a URL's query parameters, a POST request to a search endpoint might be more appropriate, despite traditionally being a GET operation. This is an exception rather than the rule.
5. Is a soft delete a HTTP DELETE or not?
Soft deletes can be a DELETE request that, instead of removing the resource, marks it as inactive. Alternatively, a PATCH to update a status could be more semantically correct, depending on the implementation. Here consistency and team agreements come into play.
6. What Are HTTP Status Codes?
HTTP status codes are standardized codes in the Hypertext Transfer Protocol (HTTP) used by web servers to indicate the status of a request's response. These codes are part of the response message from the server and help the client understand the result of their request. They are grouped into five categories, each signifying a different type of response:

1xx (Informational): Indicates provisional responses, requiring the requester to initiate a follow-up request to receive the final response.
2xx (Success): Signals that the request was successfully received, understood, and accepted.
3xx (Redirection): Means further action needs to be taken by the user agent to fulfill the request, typically a redirection to another URI.
4xx (Client Error): Indicates an error on the client's part, such as a bad request or unauthorized access.
5xx (Server Error): Signifies an error on the server's part, indicating the server failed to fulfill a valid request.
Each category has various specific codes, such as 200 OK for a successful request, 404 Not Found when a resource can't be located, or 500 Internal Server Error for general server failures.
7. How to Use HTTP Status Codes?
They are used to communicate the outcome of HTTP requests.
Clients, such as web browsers or API consumers, use these codes to determine the next steps in their process.
For example, a 200 OK status may lead to the display of content to a user, while a 401 Unauthorized status could trigger a login flow. They are essential for RESTful API design, providing a standardized method for indicating success, failure, and required actions to clients.
8. Should I Use Status Codes for Business Validation?
HTTP status codes are well-suited for indicating the technical outcome of a request (e.g., whether or not it was successfully processed by the server).
Sometimes they can also be used to some extent for business logic errors, provided there's a good match between the status code semantics and the business error condition. For common business validation errors, such as input data failing validation checks, 400 Bad Request is appropriate.
However, it's important not to stretch the semantics of HTTP status codes too far to fit business logic errors. Because in most of the cases, you need more than that.
So what do you do, return 200 OK with a Business Error in the Response body?
The best of both worlds is returning a general status code like 400 Bad Request or 422 Unprocessable Entity (for semantic errors in the request) and include a detailed error message in the response body.
This approach allows you to communicate specific business rule failures or validation messages in a structured format that clients can parse and handle accordingly.
9. Should Hypermedia Include Links to All Possible Endpoints?
Hypermedia does not necessarily mean exposing all possible endpoints directly, but providing a way to navigate the API dynamically.
It's about providing relevant links and actions based on the current resource state or context, thus maintaining a balance between discoverability and security.
For instance, a user resource might include links to related resources like a user's posts or profile settings, rather than exposing unrelated endpoints.
This approach reduces coupling and improves discoverability without necessarily exposing the full API surface.
10. How Does Versioning Fit in?
Versioning APIs is a critical aspect of designing and maintaining web services, ensuring that they can evolve over time without disrupting existing clients.
Versioning within RMM should be handled in a way that maintains the API's RESTful nature.
Techniques like using HTTP headers for version information or leveraging content negotiation allow the APIs to introduce versions without breaking HATEOAS principles or cluttering URIs with version numbers.
The Richardson Maturity Model provides a structured path towards fully RESTful services, emphasizing the importance of using HTTP verbs appropriately, considering hypermedia's role in API design, and integrating versioning thoughtfully.
By understanding and applying these principles, you can create more robust, scalable, and maintainable web services that offer greater flexibility and user experience.
P.S. If you enjoyed this post, share it with your friends and colleagues.